
The INTERNALS chapter is aimed at fellow developers who want to get a deeper understanding of how Trailblazer is built. If you plan to add features, improve or extend Trailblazer, this is your place to learn about details.
Please note that this chapter is constantly updated and extended. Are you lost? Chat to us on Zulip!
TODO: FILE LAYOUT
A normalizer is a pipeline of steps, a bit like a simple operation without the railway. The concept of normalizers is used in a lot of places in TRB: for processing DSL options as seen with #step or in Reform 3’s #property, or even in the Developer::Debugger.
In the Activity DSL, every time #step is called, a normalizer is invoked and its steps eventually produce the task(s) and the wiring. The result is then added to the Sequence instance.
The basic normalizer resides in trailblazer/activity/dsl/linear/normalizer.rb. All additional normalizers for #fail, #pass and #terminus in both Railway and FastTrack (operation) are built on top of that normalizer.
Normalizer steps usually check for options in ctx and then apply logic. Suppose you want a new option upcase_id: true in your operation DSL that uppercase the precomputed ID.
module MyNormalizer
def self.upcase_id(ctx, flow_options, _, upcase_id: nil, id:, **)
return ctx, flow_options unless upcase_id
ctx = ctx.merge(id: id.to_s.upcase)
return ctx, flow_options
end
end
Note that this function needs :id, so it has to be inserted after the ID computing step. You can extend an existing normalizer using Normalizer.extend!.
module Song::Activity
class Create < Trailblazer::Activity::Railway
Trailblazer::Activity::DSL::Linear::Normalizer.extend!(
Song::Activity::Create,
:step
) do |normalizer|
Trailblazer::Activity::DSL::Linear::Normalizer.prepend_to(
normalizer,
"activity.default_outputs", # few steps after "activity.normalize_id"
{
# "my.upcase_id" => Trailblazer::Activity::DSL::Linear::Normalizer.Task(MyNormalizer.method(:upcase_id)),
"my.upcase_id" => MyNormalizer.method(:upcase_id),
}
)
end
step :create_model, upcase_id: true
step :validate
pass :save, upcase_id: true # not applied!
# ...
end
end
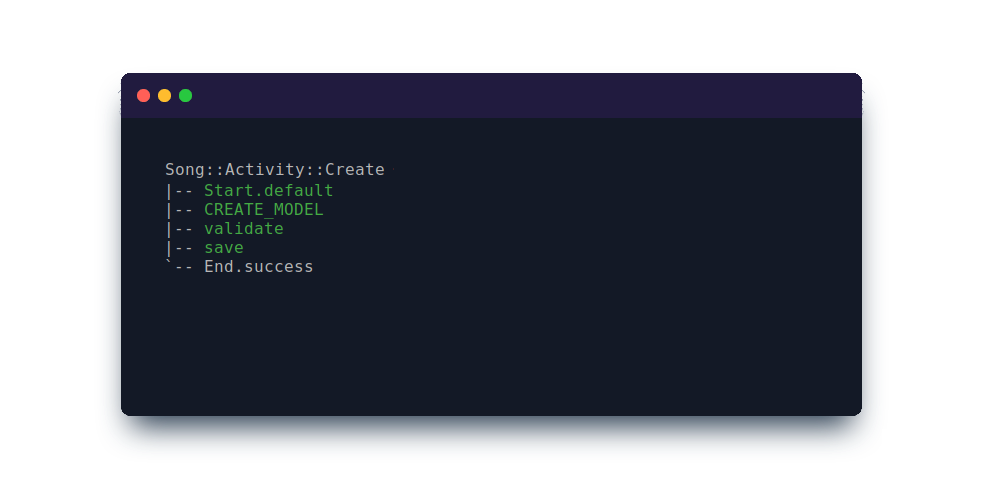
The first argument is the activity to extend. The following arguments name the normalizers to modify. In this example, only #step’s normalizer will contain the #upcase_id step.
In the trace you can see, as expected, that only the ID for :create_model is uppercased.
The dsl supports the inherit: true option to copy over particular recorded options from the replaced step in the superclass. This is implemented in "inherit.recall_recorded_options". In order to instruct the :inherit logic to record and reapply certain options, you need to mark those using Record().
If you wanted the :upcase_id option to be added automatically to the user’s option when using inherit: true the following function could be added to the above MyNormalizer.
module MyNormalizer
# ...
def self.record_upcase_id_flag(ctx, flow_options, _, upcase_id: nil, **)
ctx = ctx.merge(
Trailblazer::Activity::DSL::Linear::Normalizer::Inherit.Record(
{upcase_id: upcase_id}, # what do you want to record?
type: :upcase_id_feature, # categorize the recorded data.
)
)
return ctx, flow_options
end
end
As :upcase_id is a symbol option (unlike, for example, Out()), the :non_symbol_option for Record() is `false.
It is added as another step to the original normalizer using extend!.
Trailblazer::Activity::DSL::Linear::Normalizer.extend!(Song::Activity::Create, :step) do |normalizer|
Trailblazer::Activity::DSL::Linear::Normalizer.prepend_to(
normalizer,
"activity.default_outputs", # step after "activity.normalize_id"
{
# "my.upcase_id" => Trailblazer::Activity::DSL::Linear::Normalizer.Task(MyNormalizer.method(:upcase_id)),
# "my.record_upcase_id_flag" => Trailblazer::Activity::DSL::Linear::Normalizer.Task(MyNormalizer.method(:record_upcase_id_flag)),
"my.upcase_id" => MyNormalizer.method(:upcase_id),
"my.record_upcase_id_flag" => MyNormalizer.method(:record_upcase_id_flag),
}
)
end
The #step DSL allows to save arbitrary data in the activity’s data field.
module Song::Activity
class Create < Trailblazer::Activity::Railway
step :create_model,
model_class: Song,
DataVariable() => :model_class # mark :model_class as data-worthy.
# ...
end
end
Using Introspect::Graph, you can now read the :model_class variable from the data field.
Trailblazer::Activity::Introspect.Nodes(Song::Activity::Create, id: :create_model)
.data[:model_class] #=> Song
This is used internally to store and expose data like :extensions (which is part of the Introspect API). It’s implemented in the basic normalizer in "activity.compile_data".
As almost every task in the final activity is connected to other tasks, this wiring needs to be computed by the DSL. Two parts are required for that: the outputs the task exposes and the connectors where a particular output is connected to.
In order to do so, several steps such as normalize_output_tuples and compile_connections are added to the basic normalizer. The logic is implemented in trailblazer/activity/dsl/linear/normalizer/output_tuples.rb
The actual work happens in #compile_wirings where the connections from each output are computed from two options: :outputs, which represents all exposed outputs along with their signal, and :output_tuples associating outputs to search strategies.
One major design guideline is that :outputs is simply a list of available outputs of the step. This option does not imply any outgoing connections. Those are effectivly defined by the :output_tuples.
Internally, :outputs can be set in two different ways. When using Subprocess() this option is provided by the macro, it retrieves the outputs via the activity interface from the nested task.
When adding a simple step (e.g. an :instance_method) the Strategy’s defaulting gets invoked, and only then! Again, none of the defaulting described in the following section is executed if the :outputs option is provided by a macro or Subprocess().
After the outputs part is run, there will always exist an :outputs option for the following steps in the normalizers ctx.
There is a special outputs pipeline under "activity.default_outputs" which has the purpose to configure and provide :outputs.
Each Strategy subclass now adds its :outputs defaulting steps (e.g. "path.outputs" or "railway.outputs" to that default_outputs pipeline. Currently, the implementation is a bit confusing as we don’t have nesting in pipeline.
As an example, Railway will add outputs[:failure].
FAILURE_OUTPUT = {failure: Activity::Output(Activity::Left, :failure)}
# ...
def add_failure_output(ctx, outputs:, **)
ctx[:outputs] = FAILURE_OUTPUT.merge(outputs)
endThe FastTrack normalizer conditionally adds outputs, only if the respective option (e.g. pass_fast: true is set.
Once ctx[:outputs] is finalized, the output tuples come into play. Using the Wiring API you can configure which output goes where.
step :model,
Output(:success) => Track(:ok) # THIS is the Wiring API!Associating outputs to connectors is implemented in output_tuples.rb. After steps of this unit have been run, a new option ctx[:output_tuples] exists that connects the :outputs and can be transformed into :connections.
The running order for computing :output_tuples is as follows.
:inherit logic from "inherit.recall_recorded_options" will copy over all non-generic output tuples from the superclass to :non_symbol_options, as if they had been provided by a user.:success etc are merged before 1.).Each strategy provides defaulting for the case that no custom wiring is configured.
Defaulting steps such as "path.step.add_success_connector" are added before "output_tuples.normalize_output_tuples".
Alternatively, as with "railway.fail.success_to_failure", a particular “inherited” connector step is replaced.
This assures that the order in :non_symbol_options and the resulting order of :output_tuples is
[<default tuples>, <inherited tuples>, <user tuples>]The Wiring API allows to add outputs along with a new signal to non-nested steps.
step :model,
Output(Error, :error) => Track(:failure) # When Error is returned, go to failure track.When using the two-argument form, a Output::CustomOutput tuple is created. In "output_tuples.register_additional_outputs" this is converted to a Output::Semantic after the new signal is registered as a new output on :outputs.
The conversion allows all following output tuples code to work with Output::Semantic, only.
Several steps in the normalizer supply support for inherit: true. It is important to understand here that only custom output tuples are inherited. The :outputs option is not inherited, and neither are the default output tuples.
"output_tuples.remember_custom_output_tuples". These are stored via the generic inherit logic.Currently, we assume that strict_outputs = false. This means we filter out custom output tuples that are not supported by the new step task or activity in "output_tuples.filter_inherited_output_tuples".
In order to accomplish this, the set of all inherited custom output tuples have to be explicitely computed. at present, we do that via inherited_recorded_options[:custom_output_tuples].
Once the :outputs variable is computed, and :output_tuples are set, the actual connections can be compiled in "activity.wirings", which is a step implemented in OutputTuples::Connections.compile_wirings. The returned :wirings array contains Sequence::Search instances that, during compilation, find the next step for a particular output.
Actually, the term :wirings is misleading and should be renamed to :output_searches.
It is also possible to build custom connectors that are able to add any number of steps (actually, sequence rows) via the ADDS interface.
The actual Sequence::Row is then computed in "activity.create_row". This is where :wirings is required. The :row is pushed onto ctx[:adds] which contains all ADDS additions for this step.
The Row instance is just one of potentially many ADDS additions that are applied to the Sequence instance.
The ADDS interface is implemented in the activity gem. It defines behavior and structures for adding rows to or altering an array or sequence.
It’s used for adding steps to the taskWrap pipeline, to normalizers, and to add rows representing steps to the Sequence in the dsl gem.
An ADDS addition instance is a hash composed like so.
{
row: #<Linear::Sequence::Row >,
insert: Adds::Insert.method(:Append)
}A Row instance has to expose an #id method.
The additions are invoked using Adds.apply_adds.
The recommended way of creating ADDS additions is the “friendly interface” via #adds_for.
Assuming you had an existing pipeline creating like the one in the following snippet.
row = Trailblazer::Activity::TaskWrap::Pipeline::Row[
"business.task", # id, required as per ADDS interface
Object # task
]
pipeline = [row] # pipe contains one item.
You can then use the “friendly interface” using FriendlyInterface.adds_for to append another element behind business.task.
adds = [
[Song::Activity::Create, id: "my.create", append: "business.task"],
]
pipeline = Trailblazer::Activity.Pipeline({"business.task" => Object})
extended_pipeline = Trailblazer::Activity::Adds.(pipeline, *adds)
# => [row, #<row with Song::Activity::Create>]
Whatsoever, usually you don’t need to use the ADDS directly but through TaskWrap::Extension.WrapStatic or when working on dsl’s sequence code.
An Activity instance exposes two public methods.
Activity#call to invoke the activity.Activity#to_h that returns the Schema hash which contains all data that was collected
during compile time.This instance is usually created via a DSL, the Schema (and Activity) is created when compiled in intermediate.rb.
An Activity is created by a DSL or other layers, but it’s completely unrelated to any DSL.
It is the runtime object that actually invokes your steps.
The schema hash can be accessed using Activity#to_h. It consists of four mandatory keys.
activity.to_h[:circuit] The executable `Activity::Circuit that will actually run the task graph.activity.to_h[:nodes] A Schema::Nodes instance with an Attributes instance per activity task. Usually used with Introspect::Nodes().activity.to_h[:outputs] The output instances this activity exposes.activity.to_h[:config] A hash keeping viable data such as :wrap_static. Note that you can add to this structure during compilation.Every step (technically, it’s a task) will be run by invoking its #call method. This was a design decision to simplify building activities without having to wrap each step into some adapter that then dispatches the invocation to the actual step.
The circuit, when invoked via #call (DISCUSS: maybe that’s not necessary) runs one step after another and figures out the next step.
It uses a Runner to actually invoke each step.
The idea of the Runner is to provide different ways of invoking a step (which could also be any operation). Currently, we provide a simple #calling implementation, and one that runs each step using a taskWrap.
The trailblazer-operation gem, being ridiculously tiny, provides the following features.
Trailblazer::Operation class which is a Trailblazer::Activity::FastTrack subclass with additions.Operation.call version implemented in operation/public_call.rb.ClassDependencies module to set ctx variables directly on the operation class.Operation::Result that is returned from Operation.call and allows queries such as #success?.The operation gem is really just a syntactical sugaring on top of Activity::FastTrack. Everything else, from the #step DSL to tracing, is implemented in underlying gems.
Long-term, I’d like to remove this gem. The only useful addition is Operation.call(ctx), and this comes with a high price. The public_call.rb code introduces unnecessary complexity and needs to apply all kinds of tricks to make Operation expose two different #call methods.
Context aka ctx (or plain old options) is a core argument-specific data structure for Trailblazer. It provides a generic, ordered read/write interface that collects mutable runtime-computed data while providing access to any compile-time information. It is extracted into its own gem and can also be used independently.
ctx can be initialized when an operation is invoked at the run time or by defining dependencies at the compile time. Inside the operation, it gets passed down to every step with it’s argument position depending on step’s interface. It will contain whatever the most recently executed step has changed and hopefully contains what you’re expecting.
If you want to see what ctx modifications are being performed per step or at specific steps, you can debug it using developer’s focus_on API.
ctx’s purpose is to hold the state of your activity which can also be passed down to other nested activities using Subprocess. You can filter what such activities can or can not “see” using variable mapping. After operation’s execution using public call, the Result object wraps the context for convenient access.
In order to provide the generic interface, scoping and debugging capabilities, the “Hash” argument you provide to an operation is initialized as an instance of Trailblazer::Context::Container to build up the final ctx. This allows us to support more features on top of it like indifferent access, aliasing etc
ctx mimics as “Hash” and also allows you to use Strings or Symbols interchangeably as keys; similar to the params hash in Rails.
result = Memo::Operation::Create.(params: { text: "Enjoy an IPA" })
result[:params] # => { text: "Enjoy an IPA" }
result['params'] # => { text: "Enjoy an IPA" }
All keys are stored as Symbols by default in order to allow them to be accessible as keyword arguments.
Note that ctx doesn’t provide interchangeable keys for any nested hashes because of the performance reasons.
Most commonly found keys in ctx are 'contract.default', 'contract.default.params', 'policy.default' etc. It sometimes becomes cumbersome to access them from ctx as they can’t be defined as keyword arguments in steps.
To overcome this, it is possible to define a shorter versions of context keys using aliases. By providing aliases mapping in flow_options[:context_options], context will maintain any mutations being made on the origianl keys with
the aliases and vice versa.
options = { params: { text: "Enjoy an IPA" } }
flow_options = {
context_options: {
aliases: { 'contract.default': :contract, 'policy.default': :policy },
container_class: Trailblazer::Context::Container::WithAliases,
}
}
# Sorry, this feature is only reliable in Ruby > 2.7
if Gem::Version.new(RUBY_VERSION) >= Gem::Version.new("3.0.0")
result = AliasesExample::Memo::Create.(options, flow_options)
else # Ruby 2.6 etc
result = AliasesExample::Memo::Create.call_with_flow_options(options, flow_options)
end
result['contract.default'] # => Memo::Contract::Create
result[:contract] # => Memo::Contract::Createflow_options are passed to the nested operations via Subprocess and all given aliases will also be applied in them by default.
class Memo::Create < Trailblazer::Operation
# ...
pass :sync
def sync(ctx, contract:, **)
# ctx['contract.default'] == ctx[:contract]
contract.sync
end
endTrailblazer::Option is one of the core structure behind operation’s step API, reform’s populator API etc. It makes us possible to accept any kind of callable objects at compile time and execute them at runtime.
class Song::Create < Trailblazer::Operation
step Authorize # Module callable
step :model # Method callable
step ->(ctx, model:, **) { puts model } # Proc callable
end
It is also a replacement over declarative-option and has been extracted out from trailblazer-context by identifying common callable patterns.
Trailblazer::Option() accepts Symbol, lambda and any other type of callable as an argument. It will be wrapped accordingly to make an executable, so you can evaluate it at runtime.
Passing a Symbol will be treated as a method that’s called on the given exec_context.
option = Trailblazer::Option(:object_id)
option.(exec_context: Object.new) # => 1234567
Same with the objects responding to .call or #call method.
class CallMe
def self.call(message:, **options)
message
end
end
option = Trailblazer::Option(CallMe)
option.(keyword_arguments: { message: "hello!" }, exec_context: nil) # => "hello!"
Notice the usage of keyword_arguments while calling an Option(). They need to be mentioned explicitly in order for them to be compatible with ruby 2.7+.
And of course, passing lambdas. They get executed within given exec_context when set.
option = Trailblazer::Option(-> { object_id })
option.(exec_context: Object.new) # => 1234567
The trailblazer-developer gem provides tracing logic and the infamous #wtf? method.
trailblazer-developer >= 0.1.0
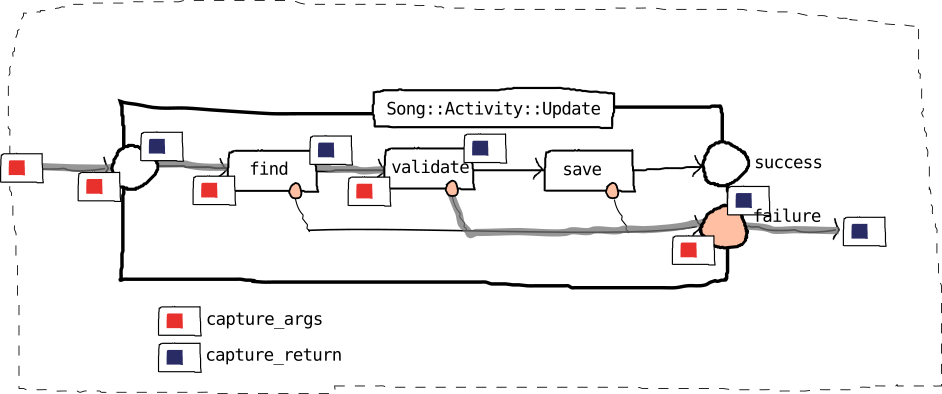
When using #wtf?, two taskWrap steps Trace.capture_args and Trace.capture_return are injected and applied around every activity step being run during the invocation of the activities (including the top activity itself). Those taskWrap extensions then invoke the snapshooters to produce a snapshot of the ctx variables before invocation of actual task, and after.
The snapshot logic is implemented in Trace::Snapshot.before_snapshooter and .after_snapshooter, leveraging the Snapshot::Version.changeset_for method to produce a diffable snapshot of ctx.
Both taskWrap extensions add the created Snapshot::Before or After instance to a Stack instance which collects the snapshots and maintains the Version object.
The stack is returned to the caller of the operation and can then be used for presentation.
Once presentation is called, an array of Trace::Node instances is generated from stack, each node comprised either of a Snapshot::Before, and its matching After, or a Node::Incomplete, when the Snapshot::After couldn’t be found (e.g. due to an exception thrown before the tracer was called).
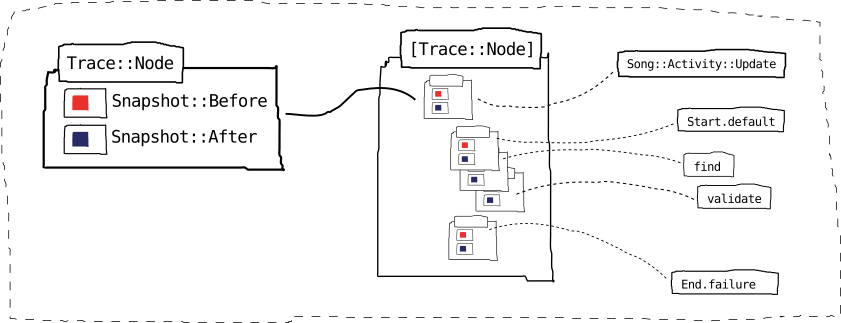
The Trace::Present.call method accepts two arguments:
1. the Stack instance
2. a block that yields this trace_node structure (along with the other options) and allows to return a hash that is then passed on to the render_method. This hash allows to configure the rendering code, and in the core renderers, config per node can be added keyed by Trace::Node instance.
TODO: add example from node_options.
After trace_nodes is computed, the specific rendering begins, and a Debugger::Trace is generated. It consists of variable versions and Debugger::Node instances, the latter basically decorating a Trace::Node.
This Debugger::Trace is then passed to either #wtf? or to trailblazer-pro’s rendering.
Debugger::Normalizer
Some notes and guidelines for core developers.
The #code_tabs helper will render two tabs ACTIVITY and OPERATION. The operation test snippet is retrieved from test/docs/autogenerated/operation_<original file name>. Extracting the snippet is done using torture mechanics both times. Sounds painful but isn’t.
< %= code_tabs "create" %>It’s beautiful!
Always write doc tests against Activity::Railway and friends. Use the conversion tool in trailblazer-core-utils to autogenerate an operation test.
Trailblazer::Core.convert_operation_test("test/docs/composable_variable_mapping_test.rb")From Ruby 3.4 onwards, Hash#inspect looks different and breaks our tests. Since we use a lot of string assertions for safety reasons, please use Trailblazer::Core::Utils.inspect to render the asserted object.
assert_equal CU.inspect(result[:params]), %({:x=>1})The Utils.inspect will make sure the rendered string contains “old style” hash syntax.
Always use Activity::Deprecate.warn when marking a method as deprecated.
def outdated_method
Trailblazer::Activity::Deprecate.warn caller_locations[0], "The `#outdated_method` is deprecated."
# old code here.
end
You need to pass one element of caller_locations to #warn. Sometimes the index changes, feel free to apply some searching for a more helpful location. Users will find the old code much faster and hopefully replace it.
Also, please test that the deprecation is actually visible.
it "gives a deprecation warning" do
_, err = capture_io do
outdated_method()
end
line_no = __LINE__
assert_equal err, %([Trailblazer] #{__FILE__}:#{line_no - 2} The `#outdated_method` is deprecated.\n)
end